Connections

M&E Journal: How AI Will Help Build Better Metadata
Story Highlights
By Ben Bendre and Noah Beltran, IBM –
In the world of M&E, it seems the formula for success is always shifting. It is no longer enough to develop content for eyeballs. The consumption patterns for media and entertainment have undergone a tectonic shift in the last few years. The rise of individual consumers and their desire to consume the content on their terms is driving content creators, owners and distributors to reinvent the way the content is monetized.
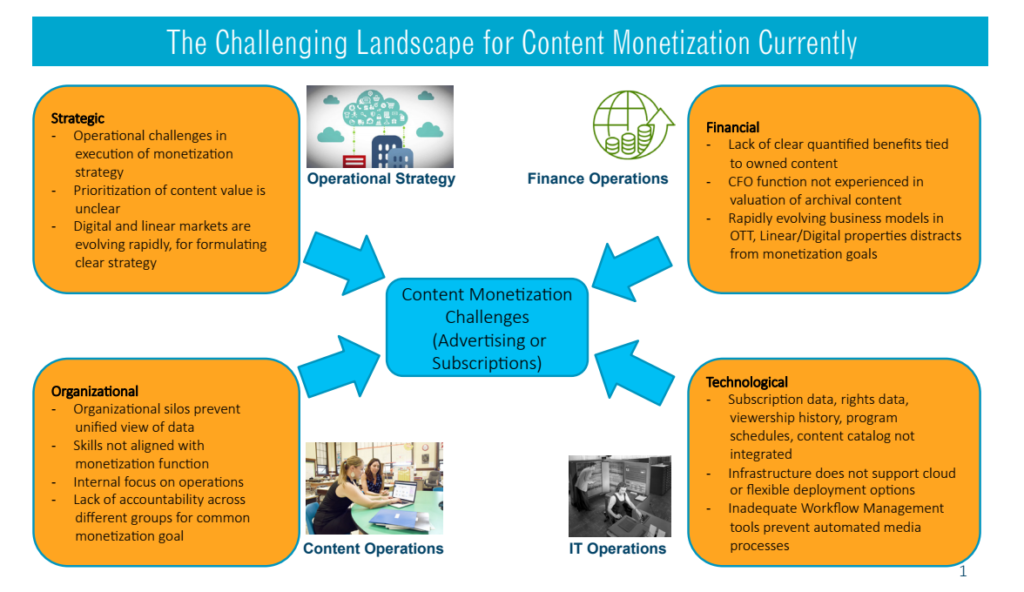
Video monetization has primarily taken one of two routes: advertisements or subscriptions. Streaming services are taking the advertising dollars away from traditional TV, but audience viewership for advertisers is still evolving. Subscription-based models must work harder to retain viewership by constantly adding or revising content in demand.
This changing landscape is forcing companies to evolve their business models to understand and define their content metadata at a much more granular level than before. They are dealing with consumers’ desire for better content recommendation engines. At the same time, advertisers are demanding better audience measurements to optimize their marketing budgets. This situation requires a new approach to creating content metadata and how content is matched to viewers’ profiles.
Complicating things, the subscriber/viewer data and content data usually reside in different silos within an organization, requiring an integrated platform to pull together a composite view. The problem of needing a much better content metadata model is not unique to content distribution and monetization. Content creators face similar problems.
Given these challenges, we have been looking at deploying intelligent technologies like IBM Watson to develop better metadata for content in an automated fashion. The ability of technologies to understand inputs like movie and TV show scripts, video and audio allow us to ingest the content and develop a much more granular metadata model.
This analysis can be performed on a variety of assets and levels, for example:
*One can parse movie scripts for generating a content signature at script level, scene level or moment level. This allows us to extract key characters from the content and build detailed personality profiles for the main characters.
*At a psychological level, viewers are likely to watch certain content if they connect with the personas in the story, or the overall theme of the content. By digitizing the personas in content, it is possible to match content to viewer preferences and tastes.
*Visual recognition capabilities of intelligent technologies allow us to extract locations, timelines, brands, and objects from the content. This further enriches the content metadata. This same capability can be utilized for content acquisition.
*Movie and TV production companies receive hundreds of scripts from a variety of sources. Manually reading each one of those scripts is a tedious task. If intelligent technology can be used to create a content signature for a script, and used as an initial filtering tool, it helps the studios to get to better scripts more quickly. In a related scenario, IBM Watson was able to generate a movie preview for the movie Morgan based on analyzing the content. Of the ten scenes that Watson found significant from the movie, nine were used in the final cut, as the last scene selected would have been a spoiler.
 Drawing connections between audiences and content
Drawing connections between audiences and content
Our approach to our intelligent media platform allows a content owner to combine data from a variety of internal and external data sources and create meaningful metadata, create richer audience profiles and a machine learning-capable content recommendation engine. The data sources can include subscriber viewership history, content catalog details, asset rights and royalty data, program tracking and scheduling data, plus external sources like Wikipedia, TV Tropes and IMDB.
A key part of the roadmap to better metadata is to create better taxonomy definitions. Taxonomy definitions should include both content classification and entity classification that helps organize the information extracted from the content. The market is still evolving for information extraction from unstructured data. Yet, with current technology it is possible to define the grammar for content information extraction. It is possible, to use English language grammar and structural rules and build an industry specific “type system,” to teach technology the meaning of industry specific terms and relationships.
This type of system, or relationships of terms, allows us to understand the concepts, timelines, people, tones, sentiments, locations and entities in the content. In turn, that leads to better understanding of how audiences can connect to that content. When the content is analyzed using visual recognition and audio/text analytics capabilities, it allows us to build a rich metadata model.
This granular metadata at each frame, moment, scene, and episode or title level can then be aggregated and stored in a data lake. This enriched metadata is the foundation of a number of use cases around content recommendations, matching with audience profiles and the ability to improve content creation workflows. .
Machine learning models for ad targeting
Machine learning models have opened doors of new possibilities for content owners and content distributors. It is possible to understand, for example, the attributes that heavily influence viewership patterns. By aggregating metadata, it is possible to evolve better strategies for collaborative filtering. Collaborative filtering refers to similar content being watched by audiences with similar profiles. If certain genres appeal to a segment, machine learning models are allowing us to understand quantitative and qualitative criteria that underlines the viewership patterns.
Another major area enabled by richer content metadata is digital and linear advertising. Advertisers are always asking for more transparency in addressing a certain demographic when they spend their marketing budgets.
These machine learning models allow both advertisers and publishers with inventory to better define who is likely to watch their content and accompanying ads. This is a big step in providing transparency in pricing of advertising inventory. It provides better tools for advertisers and publishers to optimize their respective goals of better ROI on marketing spend and higher yield optimization.
Personalization based on granular metadata helps improve content consumption and addressability of advertisements. Digital marketing and programmatic advertising can benefit immensely from better subscriber profiles and richer metadata. Identifying what content is being watched by which personas and aligning that combination to brand messaging is key for advertisers to get the most from their marketing dollars.
Streaming service companies are looking to create a flexible IT infrastructure to provide more personalized service as demand changes. These types of capabilities make it easier for companies to scale for increasing demand, without a substantial investment upfront.
In conclusion, given the emergence of new technological capabilities, we are entering a new age of much richer metadata, by building smarter media platforms that understand the spirit of the content in a meaningful way. The smarter media platforms will lead the way in the future for the industry to manage the content and leverage their archives to maintain profitability for a long time to come.
—-
Click here to translate this article
Click here to download the complete .PDF version of this article
Click here to download the entire Spring 2017 M&E Journal








